我們依然採用以上三個階段來逐步闡述實現細節。
第一階段:資料收集
事實上,收集的原始口罩資料是包含多餘的額外背景資訊。為了僅保留面部區域的照片,我們用到了MTCNN演算法進行人臉檢測。MTCNN演算法不僅可以判斷當前照片是否有人,而且若有人出現,能相應地檢測出人臉的座標位置。
![如何實現AI人臉識別及口罩佩戴檢測功能?]()
通過MTCNN進行人臉檢測,我們可以對所有的原始資料進行處理,僅保留臉部資訊,最後還需要對圖片的尺寸統一縮放到112×112。MS-Celeb-1M的圖片資料也需要進行同樣的檢測、截取、縮放操作。
我們將口罩資料按如下劃分為訓練集(訓練模型參數)和驗證集(驗證模型精度)
訓練集:1,300張口罩照片、1,300張無口罩照片
驗證集:300張口罩照片、300張無口罩照片
人臉識別資料的訓練集使用了MS-Celeb-1M,驗證集則選用了LFW (Labeled
Faces in the Wild),後者是業界普遍用於評判一個識別模型精度的基準圖像庫。
第二階段:訓練
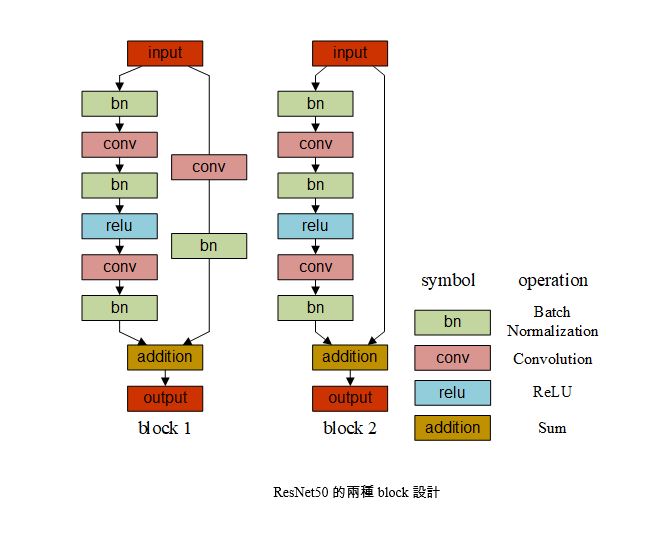
我們選用了MobileNet V2作為口罩判斷模型的網絡,MobileNet V2是一個羽量級的卷積神經網絡,該網絡的設計原則是預測精度有略微的減少的同時,顯著地減少模型參數和數學計算量,最終使模型的運算性能達到較佳的狀態。MobileNet V2的網絡架構使用到的兩種block設計,另外,我們把該網絡的資料登錄層的尺寸設定為112×112(原網絡的輸入為224×224),這也是在資料處理時需要把圖片尺寸統一為112×112的原因。
![如何實現AI人臉識別及口罩佩戴檢測功能?]()
我們使用了MrCPlusPlus提供的預訓練模型作為口罩檢測模型的初始化模型,將原網絡的輸出層修改為2(因為只有戴口罩和沒戴口罩兩個類別),然後再進行微調訓練。訓練參數設置為batch
size=32(每次取32張照片同時進行訓練),使用ADAM優化器用作網絡參數的更新,初始學習率設置為0.1,損失函數我們選用了Softmax
Loss並加入了權重L2正則化。參數更新反覆運算了40次後,模型的驗證集精度已經達到了98%,並趨於穩定。
在專案mask_wear_detection路徑下,包含以下檔結構:

./data/主要存放口罩的圖片資料
./output/存放預訓練的模型檔以及訓練後得到的模型檔
至於目錄下的Python腳本,則對應以下功能:
data_process.py:將原有的jpg檔轉換成Tensorflow的特定檔案格式tfrecords。
train_nets_transfer_learning.py:訓練口罩佩戴檢測模型。
eval_ckpt_file.py:評估模型的識別精度
freeze_graph.py:凍結模型。將訓練所得的.ckpt格式的模型轉換成最終部署的.pb格式。
inference_predict_pb.py:對單張圖片進行推理運算。
common.py:包含一些模型訓練的設置。
MobileFaceNet.py:使用的MobileNet V2神經網絡結構。
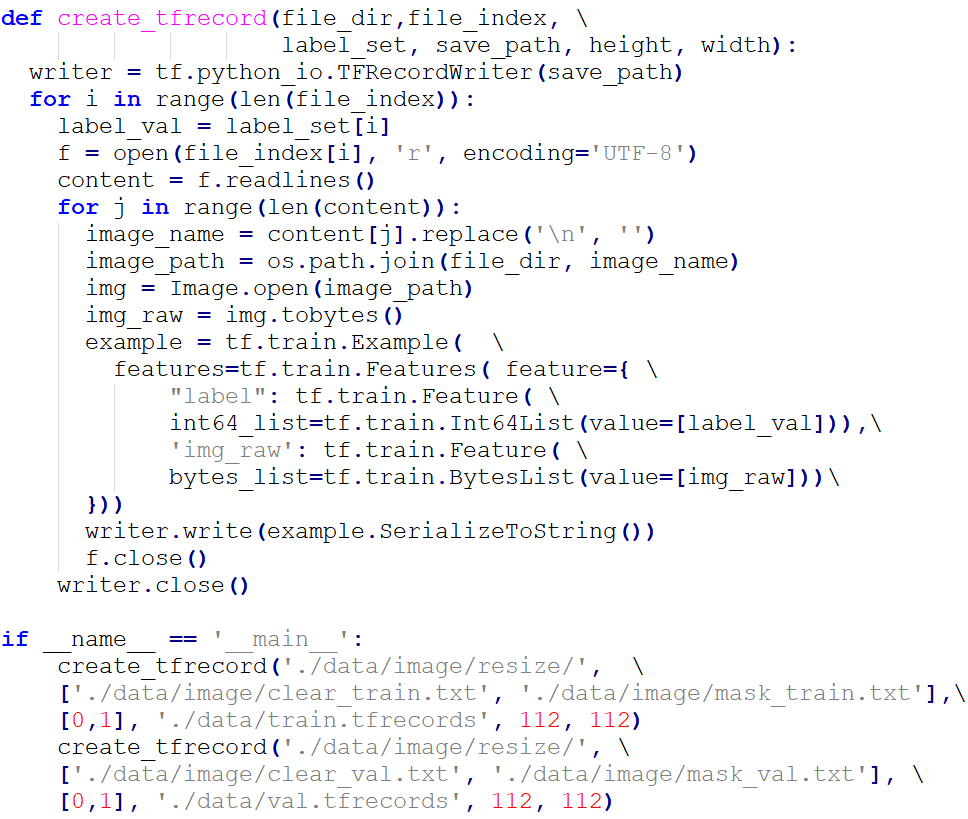
首先需要進行檔案格式轉換,打開data_process.py可以看到:
我們分別對使用預設定的clear_train.txt和clear_val.txt生成了沒戴口罩的訓練集和驗證集,mask_train.txt和mask_val.txt生成了戴口罩的訓練集和驗證集。
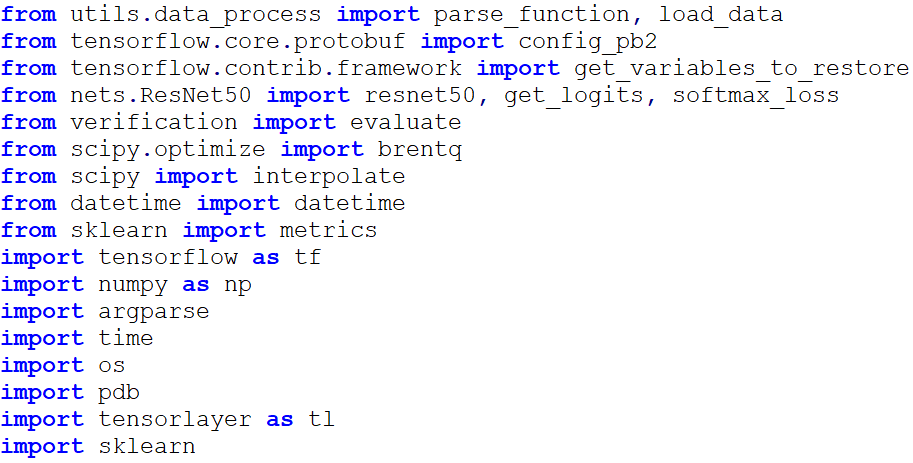
打開train_nets_transfer_learning.py,我們需要在腳本的開頭導入以下開發包
![如何實現AI人臉識別及口罩佩戴檢測功能?]()
我們設置了如下訓練超參數
![如何實現AI人臉識別及口罩佩戴檢測功能?]()
優化器默認選擇了Adam
將data_process.py中已生成的訓練集和驗證集的tfrecords檔路徑設置為train_file_path和validate_file_path,然後使用Tensorflow的iterator函數每次獲取訓練/驗證資料。
![如何實現AI人臉識別及口罩佩戴檢測功能?]()
我們對網絡的卷積權重參數進行了L2正則化處理,加上頂層的Softmax Loss,構成最終的總損失total_loss
因為我們此次訓練使用了遷移學習,我們需要導入設定的pretrained_model, 並且載入除了頂層以後的所有網路層參數作為初始化參數。
![如何實現AI人臉識別及口罩佩戴檢測功能?]()
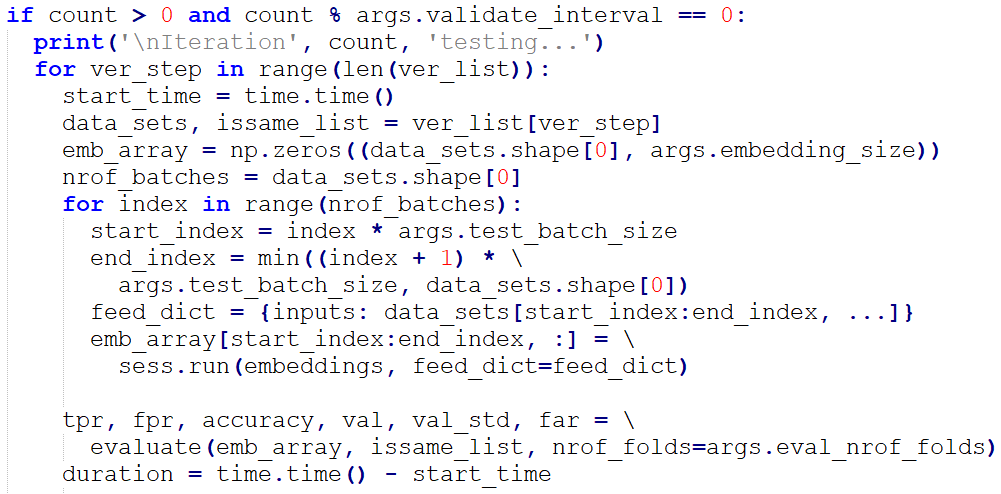
通過執行Tensorflow的會話session,我們可以針對images_train(訓練集圖片資料)和labels_train(訓練集標籤)進行參數訓練了。通過觀察total_loss_train和acc_train獲知當前訓練集的損失值(越低越好)和準確率(越高越好)。
我們設定了每訓練次數達到10次(validate_interval的值),就進行驗證集損失(inference_loss)和準確率(acc_val)計算,即時獲知當前模型的泛化能力。
若當前的驗證集準確率有提升,則以ckpt的格式保存當前的模型。
![如何實現AI人臉識別及口罩佩戴檢測功能?]()
![如何實現AI人臉識別及口罩佩戴檢測功能?]()
我們選用了ResNet50作為人臉識別模型的網絡,
ResNet50歸屬於Residual
Network系列。 Residual Network的設計思路是首次提出了直連接,即底層的特徵與高層的特徵進行迭加融合,這種設計解決了訓練過程中的梯度消失和梯度爆炸問題,使底層的網絡參數也能得到有效的訓練更新。同樣地,網絡的資料登錄層也設定為112×112。
我們參考了deepinsight的ResNet50模型,並選用了該模型作為預訓練模型,然後進行微調訓練。訓練參數設置為batch
size=8,epoch=10(訓練集的資料訓練10次),使用ADAM優化器用作網絡參數的更新,學習率按下表設置:
|
epoch
|
1
|
2
|
3
|
4
|
5
|
6
|
7
|
8
|
9
|
10
|
|
學習率
|
0.1
|
0.01
|
0.01
|
0.01
|
0.001
|
0.001
|
0.0001
|
0.0001
|
0.00001
|
0.00001
|
損失函數我們選用了Softmax Loss並加入了權重L2正則化。最終訓練得到的ResNet50在LFW的準確率能到達99.8%。
在專案InsightFace_Tensorflow路徑下,包含以下檔結構:
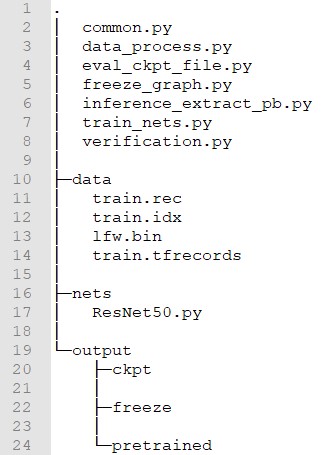
./data/存放了MS-Celeb-1M資料(train.rec和train.idx)、LFW數據(lfw.bin)以及tfrecords資料
./output/存放預訓練的模型檔以及訓練後得到的模型檔
至於目錄下的Python腳本,則對應以下功能:
data_process.py:將train.rec和train.idx轉換成Tensorflow的特定檔案格式tfrecords。
train_nets.py:訓練人臉識別模型。
eval_ckpt_file.py:評估模型在LFW的識別精度
freeze_graph.py:凍結模型。將訓練所得的.ckpt格式的模型轉換成最終部署的.pb格式。
inference_extract_pb.py:對單張圖片進行推理運算。
common.py:包含一些模型訓練的設置。
ResNet50.py:使用的ResNet50神經網絡結構。
首先需要進行檔案格式轉換,打開data_process.py可以看到:
![如何實現AI人臉識別及口罩佩戴檢測功能?]()
![如何實現AI人臉識別及口罩佩戴檢測功能?]()
我們把train.rec和train.idx檔路徑賦值給idx_path和bin_path,可以生成Tensorflow指定的檔案格式tfrecords,該生成的檔作為模型的訓練集檔。
打開train_nets.py,我們需要在腳本的開頭導入以下開發包
![如何實現AI人臉識別及口罩佩戴檢測功能?]()
我們設置了如下訓練超參數
優化器默認選擇了Adam
將data_process.py中已生成的訓練集tfrecords檔路徑設置為tfrecords_file_path,然後使用Tensorflow的iterator函數每次獲取訓練資料。
![如何實現AI人臉識別及口罩佩戴檢測功能?]()
损失函数我们选用了Softmax Loss
我們此次訓練使用了遷移學習,導入設定的pretrained_model, 然後載入除了頂層以後的所有網路層參數作為初始化參數。此處,我們需要預先將deepinsight [6]的提供的pb檔裡的網路層參數另存為npy檔。
![如何實現AI人臉識別及口罩佩戴檢測功能?]()
通過執行Tensorflow的會話session,我們可以針對images_train(訓練集圖片資料)和labels_train(訓練集標籤)進行參數訓練了。通過觀察total_loss_train和acc_train獲知當前訓練集的損失值(越低越好)和準確率(越高越好)。
我們設定了每訓練次數達到10次(validate_interval的值),就評估模型在LFW的準確率,我們使用了verification.py的evaluate函數進行準確率評估。
我們主要關注np.mean(accuracy)這項指標,假如該值有所提升,則以ckpt的格式保存當前的模型。
![如何實現AI人臉識別及口罩佩戴檢測功能?]()
值得注意的是,我們本次選用的MTCNN模型是源自OAID提供的預訓練後的人臉檢測模型。
第三階段:部署
我們選用了FLIR C3作為本專案的圖像採集攝像機,該款攝像頭能通過熱成像原理測量當前畫面目標的表面溫度。FLIR C3 SDK的開發語言是C#,因此我們選用C#作為軟體發展語言,並將AI功能編譯成dll的形式提供給軟體載入並調用。
在上一階段,我們已經訓練得到了口罩判斷模型、人臉識別模型以及現有的人臉檢測模型。我們使用Neargye編譯的Tensorflow C庫對以上三個模型進行載入、推理等操作運算。最後,我們把這些C++實現的AI功能函數編譯成了dll(因為C#調用C++源碼,需要將後者編譯成dll)。軟體最終運行的系統平臺是Windows
10。
返回閱讀更多
引用
[1] Guo, Yandong, et al.
"MS-Celeb-1M: A Dataset and Benchmark for Large-Scale Face
Recognition." european conference on computer vision (2016):
87-102.
[2] G. B. Huang, M.
Ramesh, T. Berg, and E. Learned-Miller. Labeled faces in the wild: A database
for studying face recognition
in unconstrained environments. Technical report, 2007.
[3] Sandler, Mark,
et al. "MobileNetV2: Inverted Residuals and Linear
Bottlenecks." computer vision and pattern recognition (2018): 4510-4520.
[4] Open source
code. Available from https://github.com/MrCPlusPlus/MobileFaceNet_Tensorflow_Pretrain.
[5] He,
Kaiming, et al. "Deep Residual Learning for Image Recognition." computer
vision and pattern recognition (2016): 770-778.
[6] Open source
code. Available from https://github.com/deepinsight/insightface.
[7] Open source
code. Available from https://github.com/OAID/FaceDetection.
[8] Open source
code. Available from https://github.com/Neargye/hello_tf_c_api.